

Book moth problems: how does a Hungarian data scientist choose what to read?
Here it is winter, after the holidays, and in the long evenings, more and more people find relaxation in reading. However, bookworms often encounter the problem that it is difficult to get information about a volume “spoiler-free”.
Here it is winter, after the holidays, and in the long evenings, more and more people find relaxation in reading. However, bookworms often encounter the problem that it is difficult to get information about a volume “spoiler-free”. And there are few things more annoying than when in a three-hundred-page book, even around the hundredth page, things happen that we have already read in the abstract. Hanna Szabó-Fischer looked for a solution to this.
“Of course, you can find good short texts, but I have practically banished them from my life and am trying to get this information from other sources. And the other source is the moly.hu community,” Hanna Szabó-Fischer, a data scientist at United Consult in Budapest, shared her personal experience. As stated, on the social page of book lovers, on each data sheet, users can put tags on books (for example, youth, contemporary, romantic, fantasy, novel, short story, poem, etc.). Based on these, it is relatively easy to decide whether you like a particular book or not.
At the same time, the data scientist emphasizes that world literature is so extensive and diverse that this Hungarian database and platform, of course, cannot be “omnipotent” in the field of international literature.
“In addition, goodreads.com is one of my favorites. Here, unfortunately, there is no labeling, which makes me choose between books quite like a sack cat. Satisfied with this state of affairs, I came to the decision to create an automatic labeling system for myself,” said Hanna Szabó-Fischer, who embarked on an unusual project to solve “book moth problems”.
The steps of the project
“If we were to read a short text ourselves, it would be relatively easy to categorize it, but in order for a program to interpret it, it takes a lot more preparation. First of all, you need a database that contains a lot of catchphrases and associated tags. The program will later learn patterns from these examples and categorize an unknown text. Another very important step is the preparation of the ear texts. The program will not see a single text, but a set of words, so we need to ensure that words with a clearly similar meaning to us (for example, book, books, about a book, about books) are interpreted by the machine as similar,” explained the expert from United Consult.

Hanna Szabó-Fischer went from the raw brief text to the working program, starting with data collection, word processing, then the structure of the document matrix and classification — using the process shown in the figure. Let's see them step by step, also delving a little into the professional details.
Data collection
“In order to build a classifier, I needed a relatively large set of students, which is called moly.huI created it using his database. I downloaded the titles of thousands of books in English, their subtitles and the labels that users have attached to them. For scraping, that is, downloading bulk data, I used a package called BeautifulSoup written in python,” the expert explained.
Text processing
According to Hanna Szabó-Fischer's experience, word processing works much more efficiently for English texts, and Goodreads also mostly books are uploaded in English, so it was obvious to optimize the program for English.
For word processing, he had the nltk package to help him, and he started the work by cleaning the ear texts.

Source: Toward Data Science
“With tokenization, I broke the text into words and then converted each word to lowercase, because for text recognition systems, for example, “Book” and “book” are not the same. Then I filtered out the “stop words”. These are words that appear many times in texts, but carry no value in themselves. Such are, for example, personal pronouns, entities, auxiliary verbs or just conjunctions,” the expert listed the steps.
Source:python nltk packedge

It was also an important task to interpret and manage punctuation marks that separate words and sentences. For centering and single characters, the various symbols were filtered out first, followed by the elements remaining as single characters during processing.
“Lemmatization and stemming are two similar processes called summation. During lemmatization, all words are reduced to a synonym for “root”. For example, “playing” or “played” will simply be “play”. It is important to highlight that during lemmatization, the algorithm pays attention to ensuring that the reduced word also remains a dictionary word. Stemming works with a similar logic, except that here the algorithm cuts or replaces word endings based on specific rules, so we may end up with non-dictionary words,” the data scientist described an important moment in word processing. He added that when converting numbers, Arabic numerals simply had to be converted into text.

Source: Toward Data Science
Document Matrix Construction
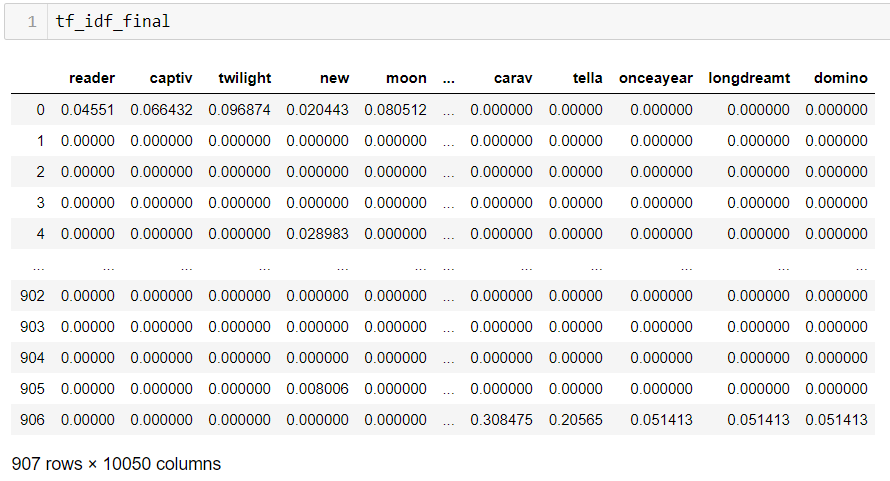
Once the cleaned data set was generated, the data scientist created a so-called document-term matrix from the words.
“It's a matrix whose rows are the documents — in my case, the snippets — and the columns are the words that occurred in the snippets. There are several ways to add value to sections of specific text and words. The simplest version, when 0 is placed in the column, which word was not included in the document, and 1 into the one that was included. It is a more sophisticated method than this, when it is not necessarily 1 in the section, but the frequency of the word, in the given document,” the expert explained.
However, Hanna Szabó-Fischer used not the former, but a third type of method: the so-called tf-idf (Term Frequency — Inverse Document Frequency) matrix. Here, values ranging from 0-1 were entered into each cell, which in themselves represent the importance (frequency) of each word in the given document and also in the corpus (set of words).
It can be calculated as follows:
- t — term (word)
- d — document (sum of words, here: 1 piece of text)
- N — Corpus size (number of all words that occur)
tf (t, d) = frequency of t in d/number of all words in d
df (t) = frequency of t in all documents
tf-idf (t, d) = tf (t, d) * log (N/ (df (t) +1))
Source:Toward Data Science
Classification
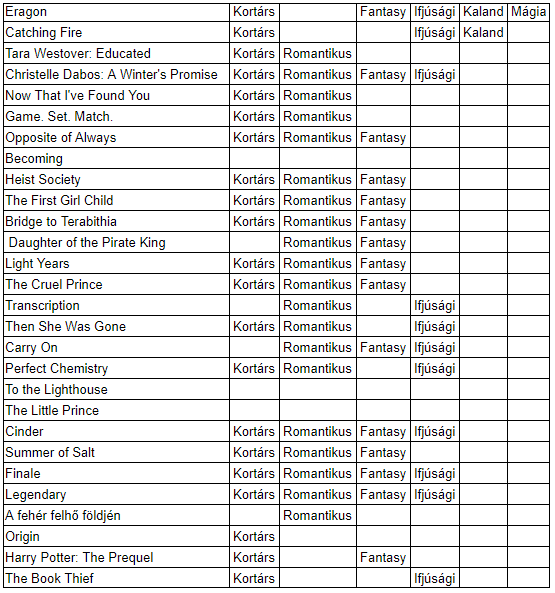
The document matrix was completed, the classification could begin. A senior fellow at United Consult separated the labels from the study set and then assessed how much volume he was dealing with.
“Roughly eight hundred different labels were collected for the thousand books. I sorted them in order of frequency and selected the fifteen that are most important to me from the most popular fifty. From each book, I stored which of the fifteen labels was true for it, and then built classifiers on the labels one by one. For this I used the sklearn package. I tried three types of algorithms (KNeighbors, Naive-Bayes and SVM), and based on their accuracy, I decided on Naive-Bayes,” he opened in the professional details. Speaking about the results, he added: for most labels, the classifiers worked with an accuracy of between 70 and 90% on the test set.

Results
After the data collection, there was the text processing, the document matrix was prepared, and then the classification was carried out. The only thing missing was the program that generates tags from the raw text. Hanna Szabó-Fischer also wrote this with the help of the steps shown in the figure below:

“I ran it through my waiting list on Goodreads and found that it tended towards unanimity. It would be appropriate to broaden my horizons,” the data scientist summed up the results.
Some examples of application of the program are:

“The results show that there are certain labels — contemporary, romantic, fantasy, youth — that are very well recognized by the program, but those that were less frequently included in the learning set — such as humorous, female/male protagonists, switched perspectives, science fiction, dystopia — have not been studied so well and do not apply them to the new short texts the labels,” said Hanna Szabó-Fischer.
Speaking about the reasons, he shared that the basic learning set was books uploaded to moly.hu in English, and in this circle the books of youth and contemporary authors, and perhaps also entertainment literature over fiction, since this database is made by users, and in the younger age group it is much more likely that someone reads English, as among the elders. Because of all this, labels related to wars, mourning, historical novels also appeared less in the student body.
“Improving the diversity of recognized labels could best be by increasing the number of learning sets and broadening the repertoire,” concluded the expert, who nevertheless heartily recommends the method described above to help anyone find a book that suits their taste without spoilers.
More results:
The code
Hanna Szabó-Fischer also shared the code, in case anyone feels like thinking about the idea further. Here's...
# SCRAPE
from bs4 import BeautifulSoup
import requests
# go through links to retrieve blurbs and tags
url = 'https://moly.hu' + link["href"]
r = requests.get(url)
# collect html
soup = BeautifulSoup(r.text, 'html.parser')
cimkek = soup.find_all('a', class_='hover_link')
fulszovegek = soup.find_all('div', class_="text")
# TEXT-MINING
def preprocessing(fulszoveg):
fulszoveg = lower_case_convert(fulszoveg)
fulszoveg = tokenizing_own(fulszoveg)
fulszoveg = stop_words_eliminator(fulszoveg)
fulszoveg = punctuation_eliminator(fulszoveg)
fulszoveg = apostrophe_eliminator(fulszoveg)
fulszoveg = single_char_eliminator(fulszoveg)
fulszoveg = converting_numbers(fulszoveg)
fulszoveg = tokenizing_own(fulszoveg)
fulszoveg = stop_words_eliminator(fulszoveg)
fulszoveg = lemming_own(fulszoveg)
fulszoveg = stemming_own(fulszoveg)
return fulszoveg
# TF-IDF
import collections
# making a dictionary which collects all the words, and collect the doc IDs for every word
DF = {}
for i in range(len(fulszovegek)):
tokens = fulszovegek[i]
for word in tokens:
try:
DF[word].add(i)
except:
DF[word] = {i}
# instead of collecting the doc IDs, we need just the counts for every word
for i in DF:
DF[i] = len(DF[i])
# all the words (keys in DF)
total_vocab = [x for x in DF]
# calcuating TF-IDF
tf_idf = {}
for i in range(len(fulszovegek)):
tokens = fulszovegek[i]
counter = collections.Counter(tokens)
words_count = len(tokens)
for token in np.unique(tokens):
tf = counter[token]/words_count
df = doc_freq(token)
idf = np.log((len(fulszovegek)+1)/(df+1))
tf_idf[doc, token] = tf*idf
doc += 1
# CLASSIFICATION
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import GridSearchCV
# train/test split
data_train=data.sample(frac=0.8,random_state=200)
data_test=data.drop(data_train.index)
# set X
X_train = data_train.drop([cimkek], axis=1)
X_test = data_test.drop([cimkek], axis=1)
# classifier for every tag
tag_list = cimkek
for tag in tag_list:
y_train = data_train[tag]
y_test = data_test[tag]
parameters = {'alpha': [0.1, 0.5, 1, 1.1, 1.2, 1.3, 1.4, 1.5, 2, 2.3, 2.6, 3, 4, 5, 6]}
naiveB = GridSearchCV(MultinomialNB(), parameters)
best_est = naiveB.best_estimator_
best_est.fit(X_train, y_train)
y_pred = best_est.predict(X_test)
print('score', best_est.score(X_test, y_test))
# PRODUCT
processed_text = preprocessing(fulszoveg)
data = instert_into_tfidf(processed_text)
result = auto_tag(data)


Get in touch
Subscribe to our newsletter
Only valuable content, no spam. Join our IT community!
© 2026 United Consult Zrt.



get in touch
Subscribe to our newsletter!
We are an innovative community who are stick together and belive in development.
© 2026 United Consult Zrt.
Get in touch
Subscribe to our newsletter
Only valuable content, no spam. Join our IT community!
© 2026 United Consult Zrt.
get in touch
Subscribe to our newsletter
Only valuable content, no spam. Join our IT community!
© 2026 United Consult Zrt.
Get in touch
Subscribe to our newsletter
Only valuable content, no spam. Join our IT community!
© 2026 United Consult Zrt.
get in touch
Subscribe to our newsletter!
Only valuable content, no spam. Join our IT community!
© 2026 United Consult Zrt.